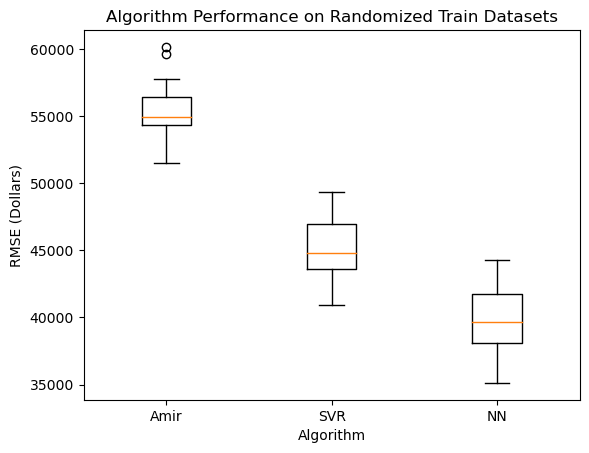
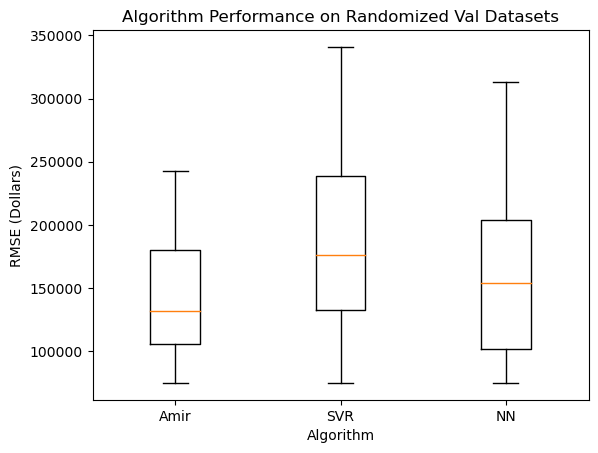
Hold on! Before we dive into the deep end and talk about how
pictures can be used to estimate house value, let's first go back
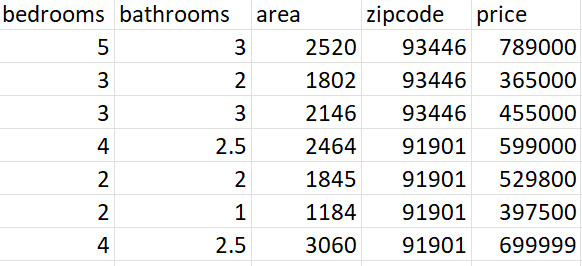
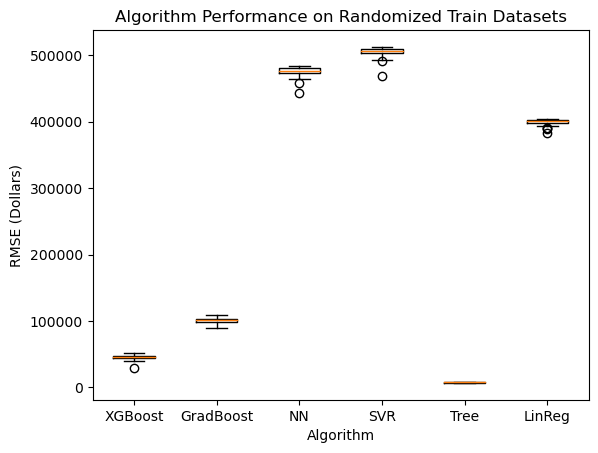
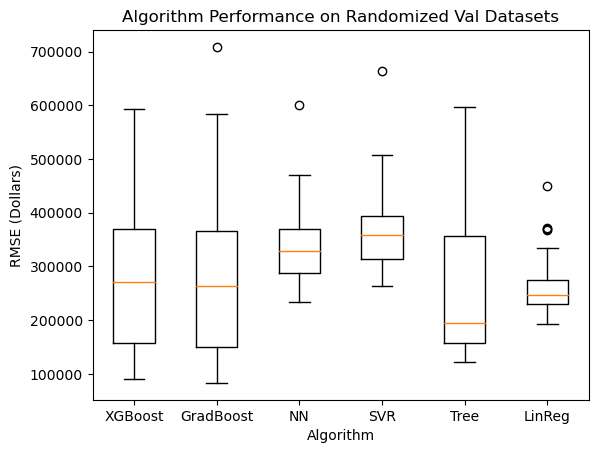
a little. As a benchmark for this project, let's first look at how
well we can estimate house value using only structured data. This
is an important decision for a couple reasons. First, machine
learning models have historically performed very well on
structured data, which is data that can be organized into tables
and columns. Second, it is well-known that the largest factor in
a house's value is its location, which can be represented by the
structured data of the house's zip code. So, a ML model's performance
on structured data is a good benchmark for how well it can perform
on unstructured data, like pictures.